
tl;dr
I forgot that the base R function type.convert() exists. Handy for ‘simplifying’ all the columns of a dataframe to appropriate data types.
Suppression depression
{a11ytables} is an R package that lets you generate publishable spreadsheets that follow the UK government’s best practice guidance.
One requirement is to replace missing values with placeholder symbols. For example, suppressed data can be replaced with the string "[c]" (‘confidential’).
Of course, R’s behaviour means it can store only one data type per column, so a numeric-type column will be automatically converted to character when you introduce at least one string value (i.e. something in "quotes").2
For example, this vector is type ‘double’ (i.e. decimals and not ‘whole-number’ integers) and has the more general ‘numeric’ class:
nums <- runif(100)
typeof(nums); class(nums)## [1] "double"## [1] "numeric"The whole thing is converted to character type if you append just one character value.
typeof(c(nums, "[c]"))## [1] "character"This is known behaviour, yes, but it causes a minor annoyance in the xlsx files output from an {a11ytables} workflow: Excel puts a warning marker in the corner of any cell in a text column that contains a numeric value.3
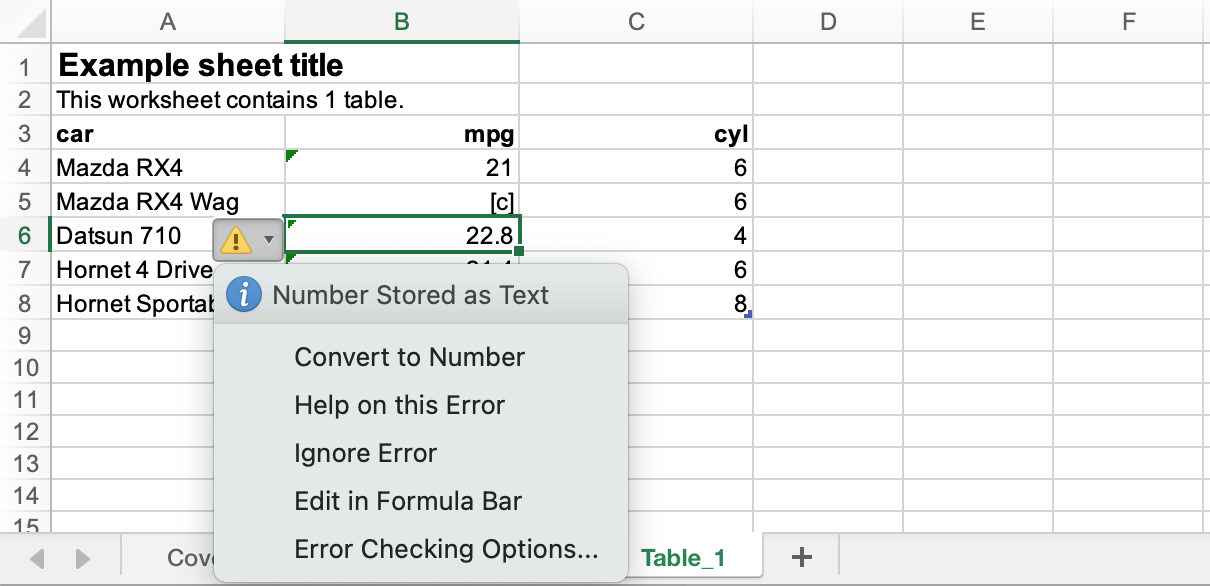
Cat left a GitHub issue related to this: columns entirely made of numbers were being marked by Excel with the ‘number in a text column’ warning. In this case, it was because Cat’s suppression process resulted in all columns being converted to character.
It would be great to convert back to numeric any columns that did not receive a placeholder symbol during the wrangling process. How can you do this?
Type specimen
Let’s consider a demo example. First I’ll attach {dplyr}, which is commonly used by stats producers in the UK government.
suppressPackageStartupMessages(library(dplyr))Here’s a very simple dataframe, tbl, to use as a demo. Column x contains values that will need to be suppressed because they’re lower than 5. There are no such values in column y.
set.seed(1337)
tbl <- tibble(
id = LETTERS[1:5],
x = round(runif(5, 0, 10), 2),
y = round(runif(5, 6, 10), 2)
)
tbl## # A tibble: 5 × 3
## id x y
## <chr> <dbl> <dbl>
## 1 A 5.76 7.33
## 2 B 5.65 9.79
## 3 C 0.74 7.12
## 4 D 4.54 6.98
## 5 E 3.73 6.58So, to borrow and simplify Cat’s approach: for each numeric column in tbl (i.e. x and y), replace any value of less than 5 with the placeholder string "[c]", otherwise retain the original value.
tbl_supp <- tbl |>
mutate(
across(
where(is.numeric),
\(value) if_else(
condition = value < 5,
true = "[c]",
false = as.character(value)
)
)
)
tbl_supp## # A tibble: 5 × 3
## id x y
## <chr> <chr> <chr>
## 1 A 5.76 7.33
## 2 B 5.65 9.79
## 3 C [c] 7.12
## 4 D [c] 6.98
## 5 E [c] 6.58So column x now contains text values and has predictably been converted to character, which you can see as <chr> in the tibble header. But notice that y is also character type despite all the numeric values being retained.
This happened because the if_else() we used to create tbl_supp required the true and false arguments to resolve to the same type. The false argument must use as.character() because true resolves to the character value "[c]".
Ideally we’d perform our suppression step but column x would end up as character and y as numeric. How can we achieve this?
Adjust my type
In this section are some methods to fix the problem by:
- Causing yourself further brainache
- Using a (relatively little known?) base R function
- Doing it ‘properly’ from the outset
Type 1: nah
Of course, we could run tbl_supp |> mutate(y = as.numeric(y)) to convert that specific column back to numeric. But imagine if you have a lot more columns and you can’t be sure which ones need to be converted.
Maybe you could apply as.numeric() across all columns? Columns of numbers stored as text will then be converted entirely to numeric:
as.numeric(c("1", "2", "3"))## [1] 1 2 3But this causes a problem for character columns that contain text, like our placeholder symbol:
as.numeric(c("1", "[c]"))## Warning: NAs introduced by coercion## [1] 1 NASo "1" becomes 1, but we’re warned that "[c]" has been converted to NA (well, NA_real_, which is the numeric form of NA).
We could do something convoluted, like see which columns didn’t gain NA values and should be retained as numeric. But that’s bonkers. This approach ultimately makes things worse because we’ve actually lost information!
Really we want to check each column to see if it contains numbers only and then convert it to numeric. How?
Type 2: better
There’s a handy base R function that I had forgotten about: type.convert().
It takes a vector and, in turn, tries to coerce it to each data type. The process stops when coercion occurs without error. As the help file (?type.convert) puts it:
Given a vector, the function attempts to convert it to logical, integer, numeric or complex, and when additionally as.is = FALSE… converts a character vector to factor. The first type that can accept all the non-missing values is chosen.
And handily:
When the data object x is a data frame or list, the function is called recursively for each column or list element.
So we can pass our entire dataframe to type.convert() and it’ll check them all for us:
tbl_supp_conv <- type.convert(tbl_supp, as.is = TRUE)
tbl_supp_conv## # A tibble: 5 × 3
## id x y
## <chr> <chr> <dbl>
## 1 A 5.76 7.33
## 2 B 5.65 9.79
## 3 C [c] 7.12
## 4 D [c] 6.98
## 5 E [c] 6.58As we wanted, our character column y has become numeric type (<dbl>) while x remains as character. Neato.
Type 3: betterer
There are probably better approaches to this problem from the outset, rather than after-the-fact application of type.convert().
As Tim has pointed out, you could actually just use the base R form of ifelse():
tbl |>
mutate(
across(
where(is.numeric),
\(value) ifelse(
test = value < 5,
yes = "[c]",
no = value
)
)
)## # A tibble: 5 × 3
## id x y
## <chr> <chr> <dbl>
## 1 A 5.76 7.33
## 2 B 5.65 9.79
## 3 C [c] 7.12
## 4 D [c] 6.98
## 5 E [c] 6.58I think people use dplyr::if_else() for (a) consistency if they’re already using tidyverse in the script and (b) it’s ‘strictness’ compared to ifelse(). if_else() will force you to declare the true and false arguments so they resolve to the same type, whereas ifelse() will silently force type coercion, which may be undesirable in some cases.
Another method would be to iterate the suppression over only the columns that need it. For example, you could do that with a simple for and if:
cols_numeric <- names(select(tbl, where(is.numeric)))
for (col in cols_numeric) {
if (any(tbl[col] < 5)) {
tbl[col] <- ifelse(
tbl[col] < 5,
"[c]",
as.character(tbl[[col]])
)
}
}
tbl## # A tibble: 5 × 3
## id x y
## <chr> <chr> <dbl>
## 1 A 5.76 7.33
## 2 B 5.65 9.79
## 3 C [c] 7.12
## 4 D [c] 6.98
## 5 E [c] 6.58This reads as ‘for each numeric column that contains at least one value less than 5, replace those values with the placeholder symbol "[c]".’
Preach to the converted types
It’s almost like this post could have just been a tweet saying ‘🤭 yo, type.convert() is 🪄magic🪄 y’all’. But this post is now a handy reference in case anyone has the same problems with Excel’s handling of {a11ytables} outputs in future.
Also I needed to hit my pun quota for the month.4
Session info
## ─ Session info ───────────────────────────────────────────────────────────────
## setting value
## version R version 4.2.0 (2022-04-22)
## os macOS Big Sur/Monterey 10.16
## system x86_64, darwin17.0
## ui X11
## language (EN)
## collate en_US.UTF-8
## ctype en_US.UTF-8
## tz Europe/London
## date 2023-04-24
## pandoc 2.19.2 @ /Applications/RStudio.app/Contents/Resources/app/quarto/bin/tools/ (via rmarkdown)
##
## ─ Packages ───────────────────────────────────────────────────────────────────
## package * version date (UTC) lib source
## blogdown 1.9 2022-03-28 [1] CRAN (R 4.2.0)
## bookdown 0.26 2022-04-15 [1] CRAN (R 4.2.0)
## bslib 0.3.1 2021-10-06 [1] CRAN (R 4.2.0)
## cli 3.6.1 2023-03-23 [1] CRAN (R 4.2.0)
## digest 0.6.31 2022-12-11 [1] CRAN (R 4.2.0)
## dplyr * 1.1.0 2023-01-29 [1] CRAN (R 4.2.0)
## evaluate 0.20 2023-01-17 [1] CRAN (R 4.2.0)
## fansi 1.0.4 2023-01-22 [1] CRAN (R 4.2.0)
## fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.2.0)
## generics 0.1.3 2022-07-05 [1] CRAN (R 4.2.0)
## glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0)
## htmltools 0.5.2 2021-08-25 [1] CRAN (R 4.2.0)
## jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.2.0)
## jsonlite 1.8.4 2022-12-06 [1] CRAN (R 4.2.0)
## knitr 1.42 2023-01-25 [1] CRAN (R 4.2.0)
## lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.2.0)
## magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.0)
## pillar 1.9.0 2023-03-22 [1] CRAN (R 4.2.0)
## pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.2.0)
## R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.0)
## rlang 1.1.0 2023-03-14 [1] CRAN (R 4.2.0)
## rmarkdown 2.14 2022-04-25 [1] CRAN (R 4.2.0)
## rstudioapi 0.14 2022-08-22 [1] CRAN (R 4.2.0)
## sass 0.4.1 2022-03-23 [1] CRAN (R 4.2.0)
## sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.2.0)
## tibble 3.1.8 2022-07-22 [1] CRAN (R 4.2.0)
## tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.2.0)
## utf8 1.2.3 2023-01-31 [1] CRAN (R 4.2.0)
## vctrs 0.6.1 2023-03-22 [1] CRAN (R 4.2.0)
## withr 2.5.0 2022-03-03 [1] CRAN (R 4.2.0)
## xfun 0.37 2023-01-31 [1] CRAN (R 4.2.0)
## yaml 2.3.7 2023-01-23 [1] CRAN (R 4.2.0)
##
## [1] /Library/Frameworks/R.framework/Versions/4.2/Resources/library
##
## ──────────────────────────────────────────────────────────────────────────────This is a Pokémon joke. I could have gone with Type: Null, but it’s too hard to draw.↩︎
There’s a sort of ‘coercion hierarchy’ in R. The order is like logical > integer > numeric > character, where the latter are ‘dominant’ to those prior (massive oversimplification). As an aside, this results in some oddities to the untrained eye:
sum(2, TRUE)resolves to3, becauseTRUEis coerced to the numeric value1(FALSEis0) and so we get 2 + 1 = 3.↩︎You can dismiss these warning markers in the Excel GUI, but I don’t think it’s possible to suppress these markers programmatically and proactively in {a11ytables}. Note also that {a11ytables} cheats a bit here for sake of presentation. The
generate_workbook()function guesses that the column was intended to be numeric and adds style information to right-align the values in the output xlsx, which is how numeric values are normally treated in Excel.↩︎Turns out there’s literally such a thing as type punning.↩︎